
GTC 2026 Review: How NVIDIA Is Redefining the AI Ecosystem — From Compute Competition to Infrastructure Transformation
A Turning Point in the AI Wave

On March 16, 2026, Jensen Huang delivered a two-hour keynote at the annual NVIDIA GTC conference in San Jose, unveiling a series of major announcements including the Vera Rubin platform, Groq-3 LPU, Vera CPU, Space-1 space module, and NemoClaw, while also previewing the next-generation Feynman platform.
The presentation has been described by industry observers as the “Burning Man of AI”, and marks another milestone for NVIDIA—twenty years after the introduction of CUDA—in redefining the future of computing.
Huang emphasized that the explosive demand for artificial intelligence has increased global computing requirements by a factor of one million within just a few years. He projected that cumulative orders between 2025 and 2027 could reach $1 trillion, reflecting the unprecedented scale of AI infrastructure investment now underway.
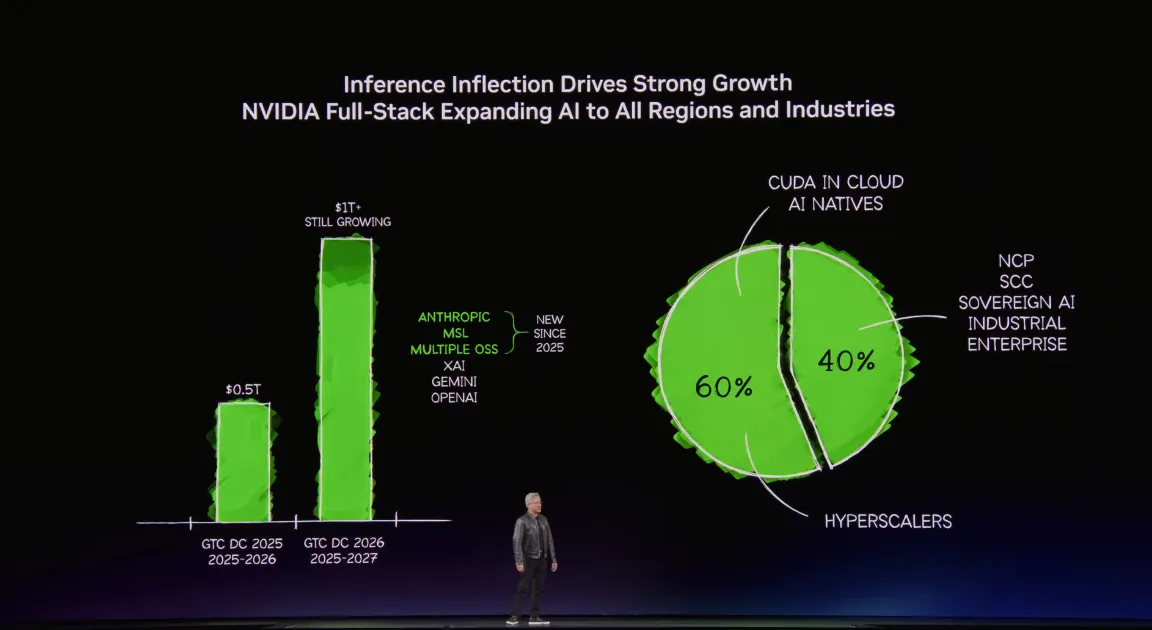
This report provides an in-depth technical analysis of the technologies introduced at GTC 2026, covering their architectural design, industry significance, and future development trajectories. The discussion spans hardware architecture, software stacks, industry collaborations, and emerging space-based opportunities, offering a comprehensive view of NVIDIA’s evolving AI ecosystem.
To ensure rigor and balance, this report synthesizes insights from official press releases, technical blogs, media analysis, industry commentary, and scientific publications, with the goal of reconstructing the most accurate technical picture possible. It also includes an in-depth discussion of the so-called “shrimp farming” concept—a metaphor emerging around OpenClaw / NemoClaw—and its broader implications for the AI infrastructure ecosystem.
Overview of the Vera Rubin Platform
Design Philosophy
The Vera Rubin platform represents a fully integrated AI factory stack, composed of seven core chips and five rack-scale systems. Its design aims to support the massive inference throughput and ultra-low latency required by next-generation agentic AI systems and Mixture-of-Experts (MoE) models.
During the keynote, Huang described Vera Rubin as a system that is “vertically integrated yet horizontally open.” The platform emphasizes co-design across multiple layers of the computing stack—from silicon chips and networking switches to storage systems and AI software frameworks.
The platform’s name honors the astronomer Vera Rubin, who discovered key evidence for dark matter. Huang noted that just as Rubin’s discoveries expanded our understanding of the universe, the next generation of AI data centers may extend beyond Earth into orbit, a vision symbolized by NVIDIA’s newly introduced space computing modules.

Seven Chips and Five Rack-Scale Systems
The Vera Rubin platform is built around the following seven core chips:
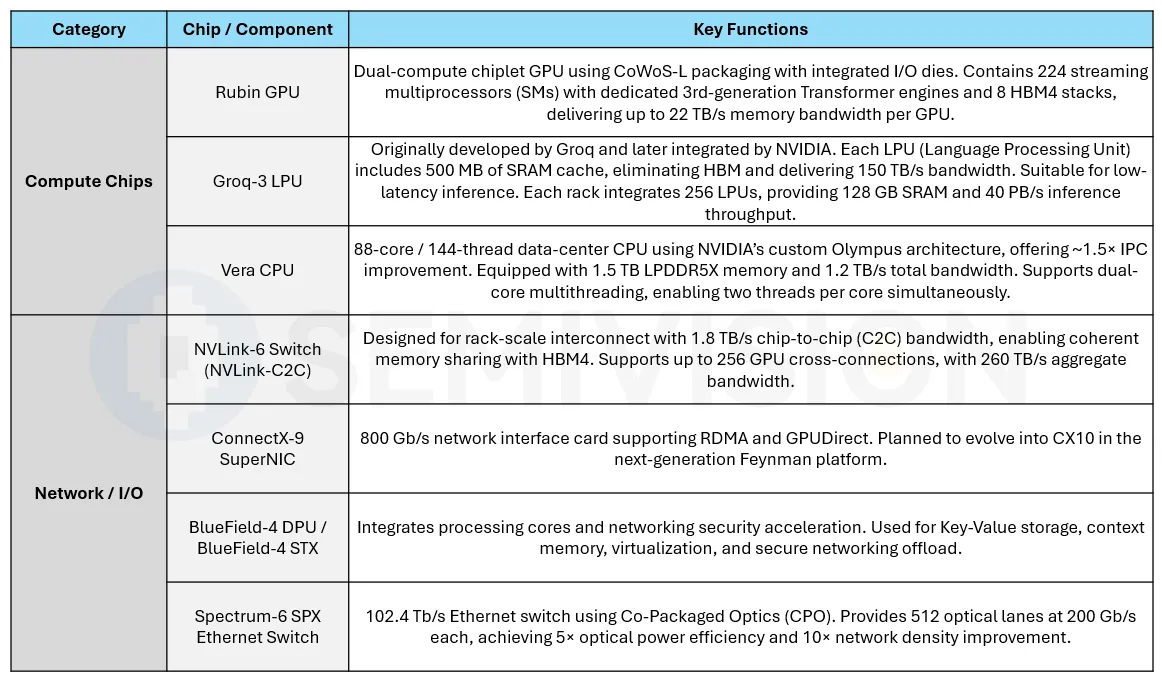
The platform is organized into five rack-scale systems based on functionality:
- NVL72 GPU Rack
Contains 72 Rubin GPUs and 36 Vera CPUs, delivering 20.7 TB of HBM4 memory and 1.6 PB/s memory bandwidth. The system is designed to run Mixture-of-Experts (MoE) models and support inference workloads generating tens of millions of tokens per second. - Vera CPU Rack
Integrates 256 liquid-cooled Vera CPUs, capable of maintaining 22,500 parallel CPU sandboxes. It is primarily used for AI agents, reinforcement learning workloads, and development environments. - Groq-3 LPX Rack
Equipped with 256 Groq LPUs, providing 128 GB of SRAM and 40 PB/s of bandwidth, specifically optimized for ultra-low-latency inference. - BlueField-4 STX Storage Rack
Provides massive context memory (key-value cache) to support fast lookups during inference for models with tens of billions of parameters, reducing the memory burden on GPUs and LPUs. - Spectrum-6 SPX Network Rack
Utilizes 102.4 Tb/s co-packaged optical switches and 200 Gb/s optical channels, enabling 800 Gb/s to 1.6 Tb/s ultra-low-latency networking between racks.
Two New System Forms: NVL72 and the DSX Factory
- NVL72 Supercomputer
Composed of 18 DGX Rubin NVL72 racks, totaling 1,296 GPUs and 640 TB of HBM4 memory, forming a supercomputer capable of 3.6 EFLOPS inference performance and 700 PFLOPS training performance. Such systems are designed for companies like Anthropic, OpenAI, and Meta to train multi-agent AI models. - DSX AI Factory Reference Design
NVIDIA introduced DSX Air and the Omniverse DSX Blueprint, allowing enterprises to simulate AI factories virtually before building physical infrastructure. This enables customers to optimize data center layout, cooling systems, power distribution, and network architecture prior to deployment.
Related News



